Тень независимости: ИИ сможет самообучаться на текстах без помощи человека
Опасна ли для людей новая степень свободы нейросетей

Российские специалисты создали технологию, благодаря которой ИИ сможет самостоятельно готовить текстовые данные для обучения нейронных сетей. Ученые использовали для этого ChatGPT. До последнего времени делать эту работу мог только человек — монотонный и трудоемкий процесс занимал до нескольких месяцев. Теперь компьютер сможет выполнять эти операции в три раза быстрее. По мнению экспертов, в автоматизации разметки нет ничего удивительного, так как нейросети уже давно выполняют и более сложные логические задачи. При этом вероятность того, что новая степень свободы искусственного интеллекта может привести к выходу его из-под контроля, невелика.
Разговор с самим собой
Специалисты МФТИ разработали методику, которая позволяет нейросетям самостоятельно готовить текстовые данные для обучения искусственного интеллекта. Теперь это автоматически смогут делать большие языковые модели, самая знаменитая из которых — ChatGPT. Обязательную предварительную работу называют разметкой, до последнего времени ее могли делать только люди — аннотаторы либо специально подобранные краудсорсеры (сотрудники из внешней команды, которые улучшает работу ИИ).
Они тщательно разбирают большое количество примеров, из которых машина выделяет закономерности. Информация должна быть правильно подготовлена, чтобы ИИ мог сделать верные выводы. Однако это трудоемкая задача, требующая выполнения множества монотонных операций. В итоге на нее может уходить до нескольких месяцев. Благодаря использованию ИИ этот процесс будет проходить в три раза быстрее и в два раза дешевле, чем раньше. Правда, полностью стать независимыми от людей машинам пока не удастся — им понадобится помощь с построением иерархии.
— С помощью большой языковой модели можно добиться высокого качества обработки информации. Однако для этого потребовалось создать многоступенчатую иерархическую схему для разметки. В таком случае в процессе обучения эксперты требуются только для этой работы, — сказала исследователь и аналитик лаборатории нейронных систем и глубокого обучения МФТИ Мария Молчанова.
При разработке автоматизированной системы специалисты с помощью ChatGPT попробовали сымитировать человеческую разметку лингвистических данных для обучения моделей. Для составления системы привлекли опытных экспертов — лингвистов, которые разработали схемы аннотаций. В результате эти инструкции улучшили качество обработки сообщений.
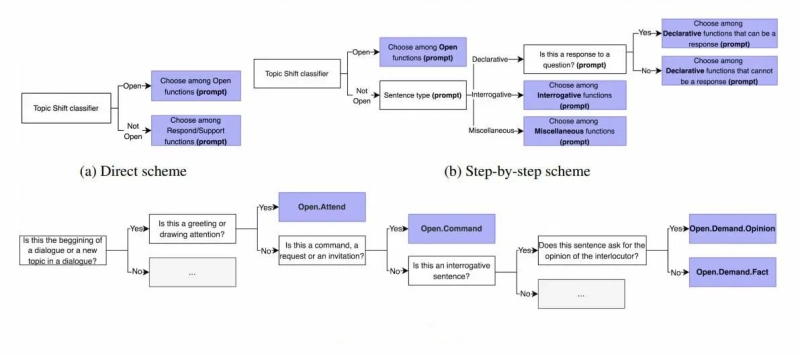
Пример схемы разметки
— Мы изучили разметку дискурса в диалогах экспертов и больших языковых моделей. Пришли к выводу, что c помощью последней можно добиться качества обработки информации, сравнимого с краудсорсерами. Преимущества автоматизированного подхода в том, что это намного быстрее и дешевле. К тому же модель размечает данные более системно, — сказала Мария Молчанова.
Разработанная методология разметки может широко применяться для аннотации лингвистических данных. Ее успешно апробировали для обработки диалогов для обучения чат-ботов в рамках научных исследований лаборатории.
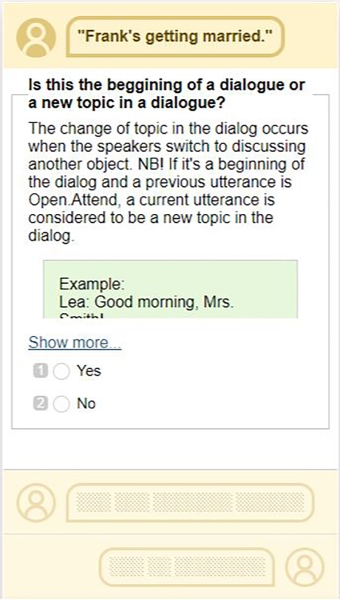
Интерфейс разметки в процессе краудсорсинга
— Эксперты тратят в среднем 14,5 минуты на разметку одного диалога, краудсорсеры — 29 минут. Время, необходимое для выполнения задачи с помощью ChatGPT, всегда разное — в целом небольшой диалог может быть аннотирован за 10 минут. Стоимость работы с использованием ChatGPT варьируется в зависимости от длины диалога примерно от $0,03 до $0,07, в то время как работникам краудсорсинга необходимо платить от $0,12 до $0,22, — сказала исследователь лаборатории нейронных систем и глубокого обучения Лидия Остякова.
Есть ли опасность
Если большие языковые модели успешно справляются с довольно сложными логическими конструкциями, их применение для разметки и аннотирования текстовой информации кажется совершенно естественным, считает ведущий эксперт Центра компетенций Национальной технологической инициативы (НТИ) «Искусственный интеллект» на базе МФТИ Александр Родин.
— Широкое внедрение самообучения языковых моделей может упростить манипуляции с результатами их работы и создание фейков, как это происходит, например, на YouTube или в соцсетях. Если массовый пользователь не обладает достаточным культурным и образовательным базисом, его нетрудно будет убедить в том, что черное — это белое, апеллируя к «железобетонному» аргументу — «так искусственный интеллект решил», — сказал Александр Родин.

По его словам, необходима жестокая экспертная цензура всего контента, сгенерированного ИИ, вне зависимости от технологии обучения конкретного алгоритма.
Подход, предложенный в МФТИ, применяется в самых разных областях. Большие языковые модели мало какие задачи могут выполнять полностью, но создавать на их основе решения, которые ускоряют или упрощают работу живых специалистов, — очень частый сценарий, отметил управляющий директор Технологических конкурсов НТИ Up Great Юрий Молодых.
— Благодаря такой автоматизации искусственный интеллект из-под контроля выйти не сможет. Вообще это непродуктивный метод анализа безопасности нейросети. Гораздо лучше рассматривать безопасность не выхода из под контроля технических решений, а ошибки в дизайне системы, которые могут привести к деструктивным последствиям, — пояснил Юрий Молодых.
В данном случае серьезные риски маловероятны, но не исключены. Если, например, нейросеть после такого обучения будет обеспечивать работу критической инфраструктуры, то ее нужно будет серьезно тестировать, добавил специалист.



